
Manipulating files filled with data is one of the absolute basics of programming. Files need to be split down, reduced, or otherwise modified to be used by a script with particular requirements. Bash, having been around as long as it has, is armed with a lot of tools for such purposes. One of those is the split command, which allows a specific file to be divided according to the instructions put up using the configuration options provided by the user. Today we will see how to use the split command to best suit our varying needs.
Bash Split command basic syntax
split [OPTION] [FILE] [PREFIX]
The [OPTION] includes many options we will see in detail in a minute. This includes various options, such as splitting by the number of lines, bytes, chunks, etc.
The [FILE] is the file name that needs to be split.
When a file is split, it will result in multiple files, which need to be named. There is a default way of naming those files, but the [PREFIX] part helps to do it desirably.
The most basic example of this command looks like this:
split sample.txt
Here, the file sample.txt contains numbers from 0 to 3003. Now, if we run the command and check the ends of the different files:
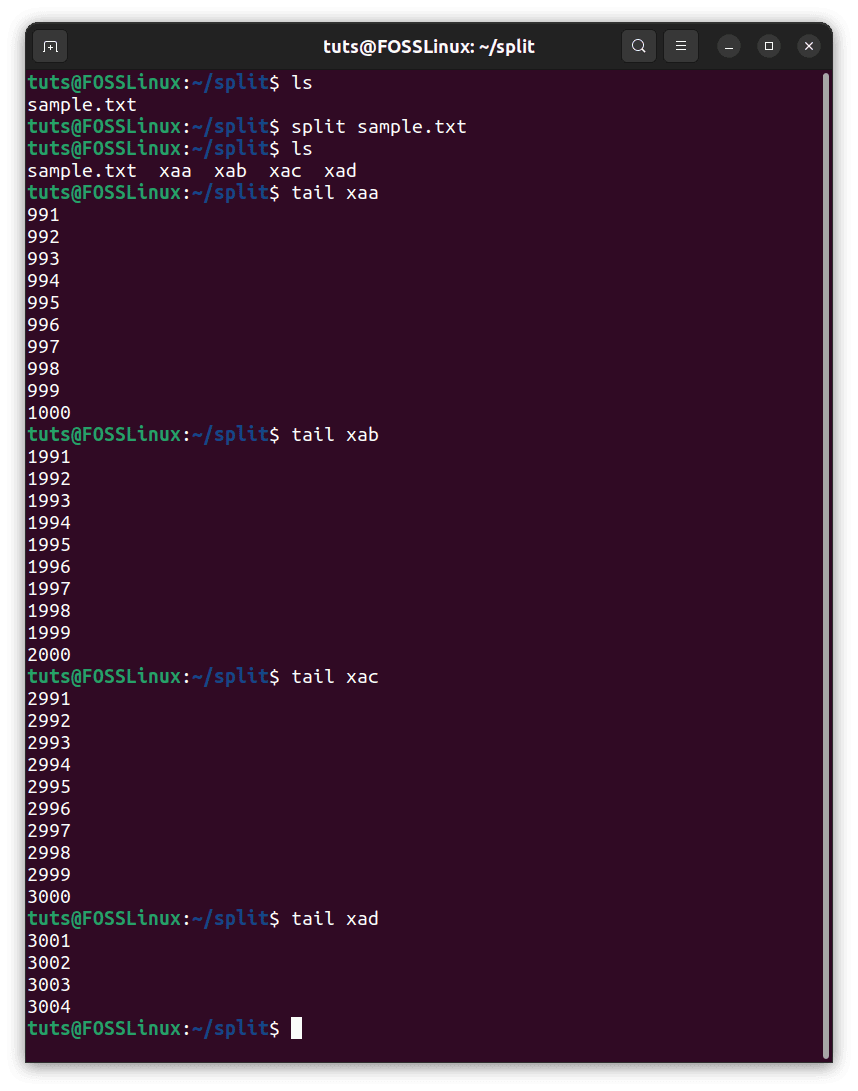
Basic usage of split
If we use the split command with no other flags or specifications, we see that it will split the file into files of 1000 lines each. This simple example shows that even the most straightforward case splits the file into ones with 1000 lines, demonstrating the sheer scale of the files that need to be dealt with regularly.
Flags for different kinds of splitting
The default of splitting files is a particular case. In most cases, you will probably need something different in value and basis. The split command allows for that very well.
Split by number of lines (-l)
As we have already seen, the default split settings divides a file into ones with 1000 lines each. There is, obviously, the option of changing the number of lines while splitting by lines. This is included in the -l flag. Using the same file and dividing it by 500 line files:
split -l 500 sample.txt
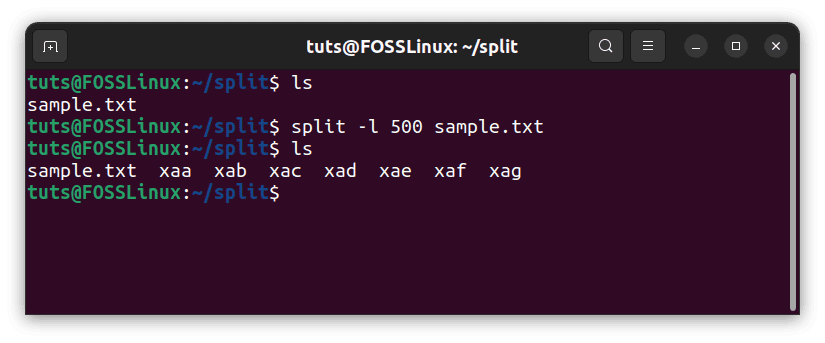
Splitting by the number of lines
As expected, this results in 7 files because the number of lines that sample.txt has is a little over 3000.
Split by number of chunks (-n)
Another way to divide the files, which makes a lot of sense in most cases, is to divide the file into chunks of equal size. The only thing required to say here is how many chunks the file needs to be split into. For example, sample.txt holds lines starting from 1, to 3003. It can be divided into 3 equal files of 1001 lines. We use the -n flag for this.
split -n 3 sample.txt
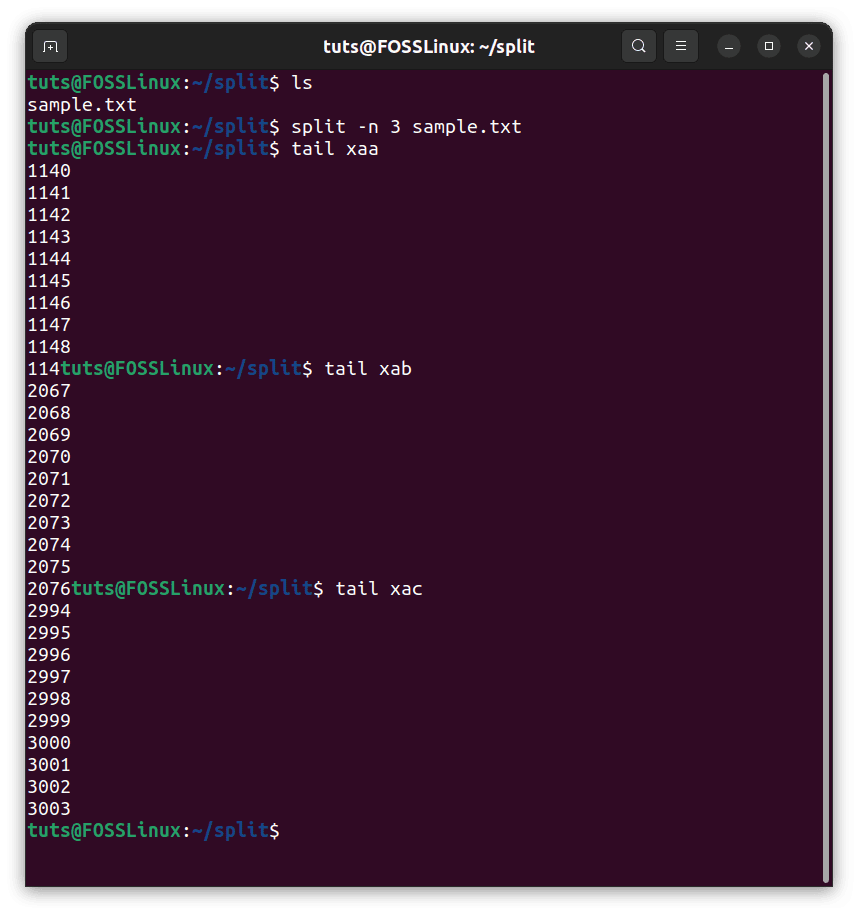
Splitting by number of chunks
The result is unexpected, though. Well, there is a perfectly reasonable explanation for that. In this file, there is a newline character at the end of each line. Going strictly by byte size, even that occupies one byte, and that is why the division seems as if it is irregular. But if you check the sizes of these files with ls, you can see that they are indeed equal sized.
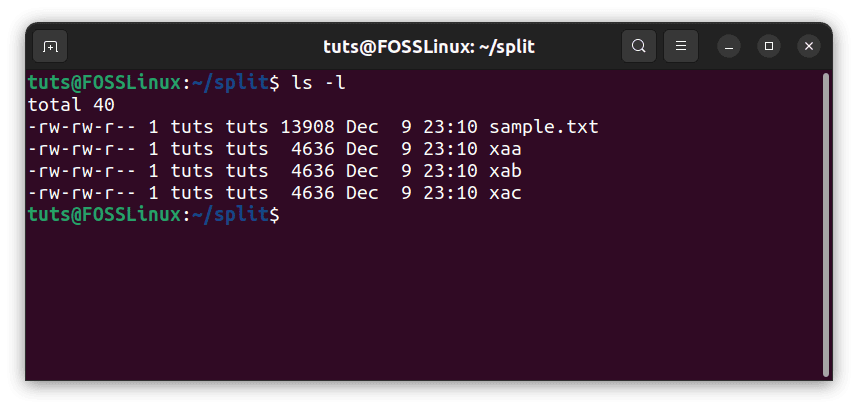
Checking file sizes after splitting by chunks
Split by number of bytes (-b)
Lastly, and still very useful, you can divide files by the number of bytes. If you run split with this flag, each file will be of the mentioned size, except for the last file, which contains the leftover bytes. For the byte size, we use the -b flag. Again, for example, with the same file and using 4500 bytes:
split -b 4500 sample.txt
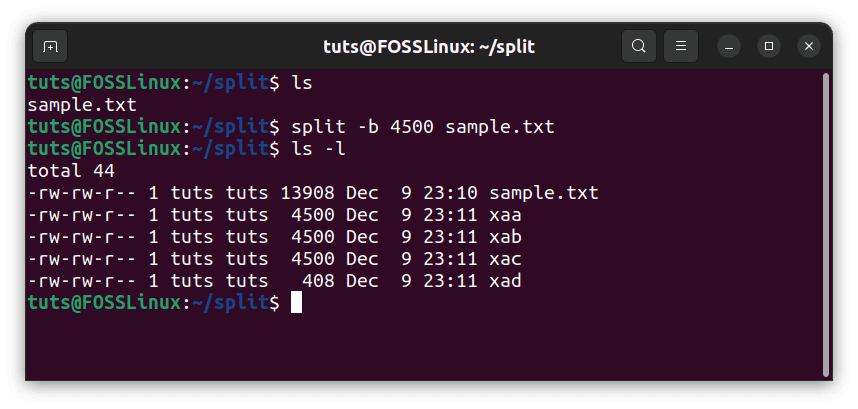
Splitting by the number of bytes
As we can see, the last file measures 408 bytes, containing the leftover bytes from the last 4500-sized file.
Flags for name modification
As we have seen so far, the names are generated as ‘xaa’, ‘xab’, and ‘xac’, going from ‘xaa’ to ‘xzz’. But, again, in some cases, you might want the files to be named differently. There are several ways to do that, which we will see now.
Verbose flag (–verbose)
Before explaining the variations in naming, we should see the verbosity option, which lets us know the file names as they are being created. Using this on the last command:
split -b 4500 sample.txt --verbose
As you can see from the result, Bash displays the names of the files.
Suffix length (-a)
The suffix is the part after ‘x’ in the general naming convention. As seen from the examples we did before this, the default length of the suffix is 2, as it goes from ‘xaa’ to ‘xzz’. One may need this length to be longer or shorter (one), even. This can be done using the ‘-a’ flag. For example:
split -b 4500 -a 1 sample.txt --verbose
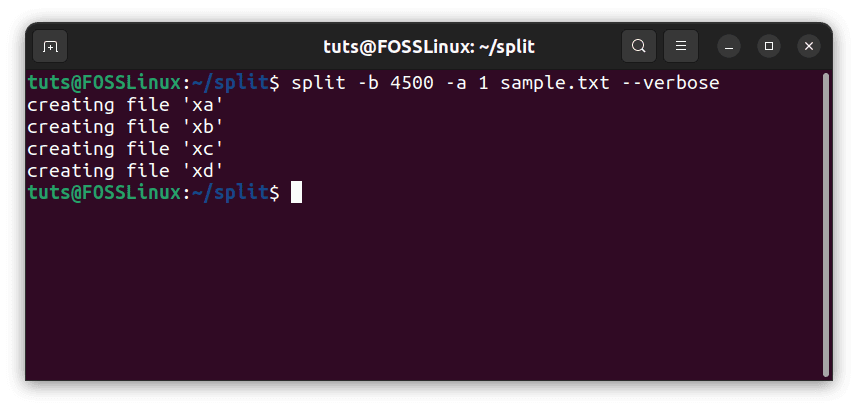
Shortening the suffix
As seen from the result of this command, the file suffixes are only 1 character long now. Or:
split -n 3 -a 4 sample.txt --verbose
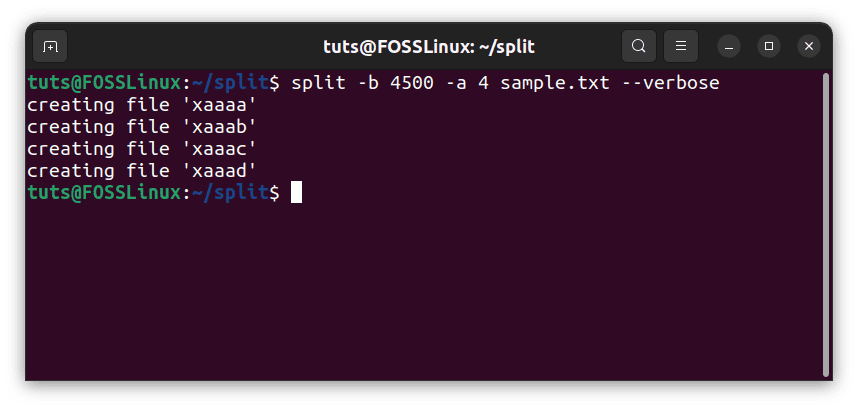
Lengthening the suffix
This makes the suffix length of 4 characters.
Numeric suffixes (-d)
Another likely scenario is that you might need numerical suffixes instead of alphabetical ones. So how do you do that? With the -d flag. Again use it on the last command:
split -n 3 -d sample.txt --verbose
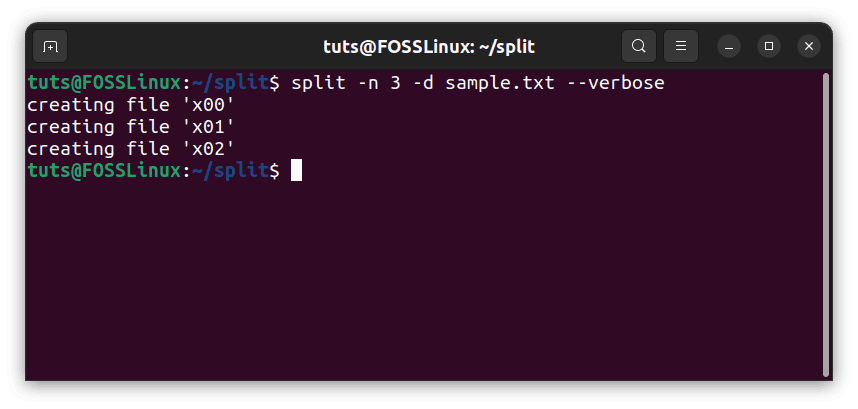
Numeric file naming
You can even use this in conjunction with the -a flag, varying the length of the numerical part of the name:
split -n 3 -d -a 4 sample.txt --verbose
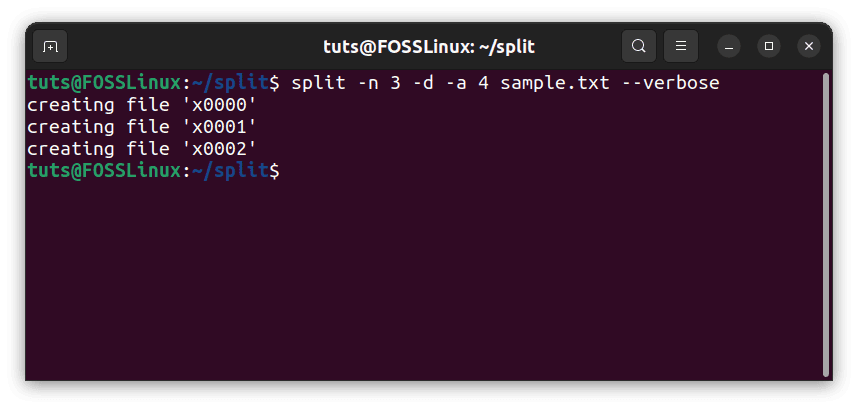
Longer numeric naming
Hex suffixes (-x)
Apart from a base 10 decimal numerical naming system, in a computer system, you might want a hexadecimal naming system. That is also very well covered with the -x flag:
split -n 20 -x sample.txt --verbose
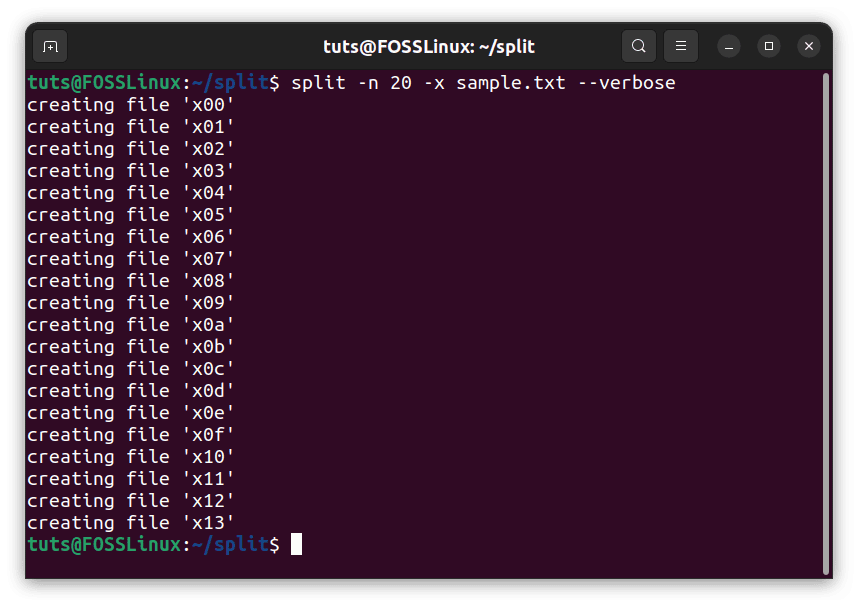
Hex code naming
Again, you can use it with an -a flag to change the length of the suffix string.
Remove empty files (-e)
A common error that occurs while splitting files, especially by a number of bytes or chunks, is that often files are generated that are empty. For example, if we have the file with this content:
abcd as asd
And we try to split this into 25 parts; the files that will be generated are:
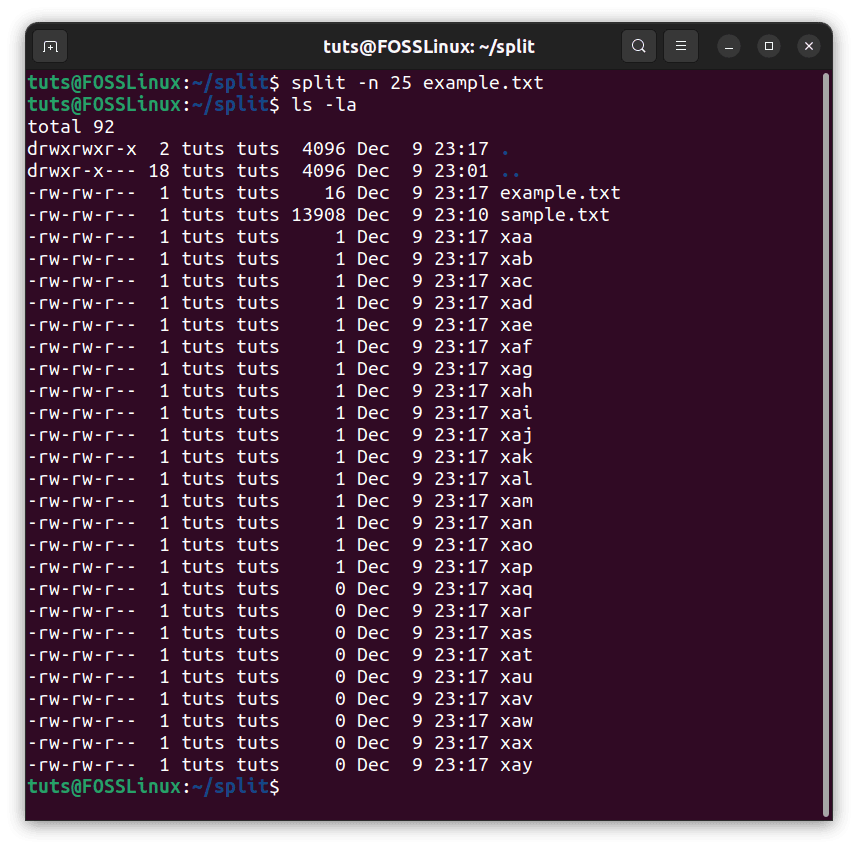
Empty files are generated
Now, as we see the individual files, some files are empty. Using the -e flag, we can avoid such a scenario:
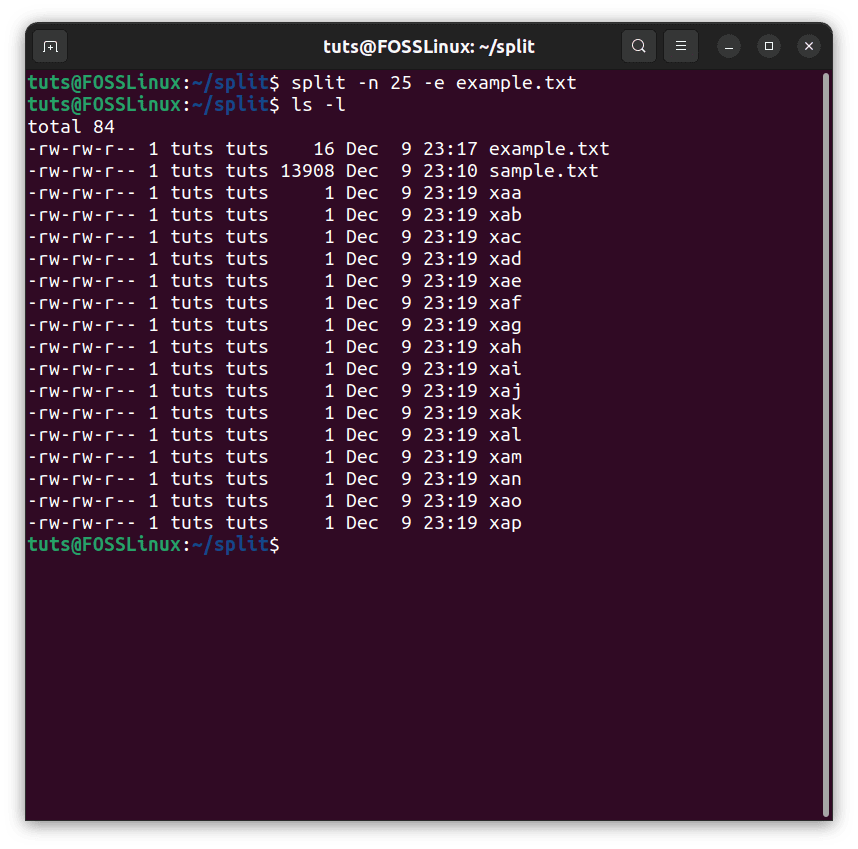
Preventing the creation of empty files
Conclusion
The split command, as we mentioned before, is handy in the context of Bash scripting. These are the basic tools that are necessary for regular tasks. The split command is a special case, one of many, that makes Bash as great as it is today. We hope that this article was helpful. Cheers!