
Wildcards, a.k.a. meta characters, are a godsend when it comes to searching for particular filenames from a heap of similarly named files. For example, by using Wildcards in Linux, you can use the ls command, rm command, or any other Linux command for that matter, on multiple files as long as they match the defined criteria.
In this read, we will discuss how you can use Wildcards in Linux to streamline your workflow and become more productive. But first, let’s take a quick look at the most powerful and commonly used wildcards in Linux:
- The Asterisk (*): The (*) wildcard represents any number of unknown characters. This is useful when searching for documents or files but only remembering a part of its name.
- The Question Mark (?): The (?) wildcard represents only one unknown character. This is useful when you have a list of similarly named files and unsure of a few characters.
- The Bracketed Characters ([ ]): The ([ ]) wildcard – the 3rd bracket and not the 1st bracket – is used to match any occurrences of characters defined inside the brackets. This option is handy when dealing with uppercase and lowercase files, as we will see later.
Now, I realize that all of this information makes no sense if you have never dealt with wildcards before. However, to help you clear your confusion, we have put together a detailed guide, including 10 examples, to make sure that you properly understand the function of wildcards and start using them yourself.
Examples of Matching Filenames Using Wildcards
To start, let’s use all the various wildcards we discussed earlier and see how to use them to match filenames. To do this, we’ll be using the following set of files:
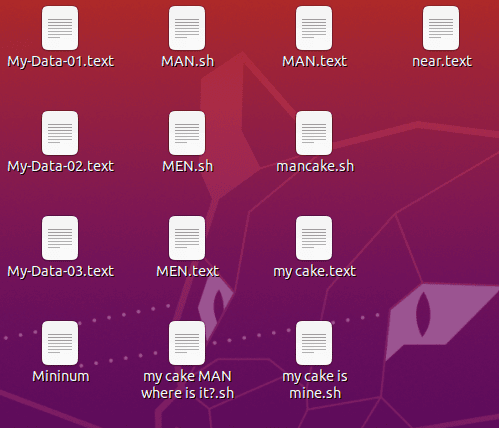
- This command will match all the file names that start with the letter M and ending with one or more occurrences of any character.
$ ls -l M*
Output:
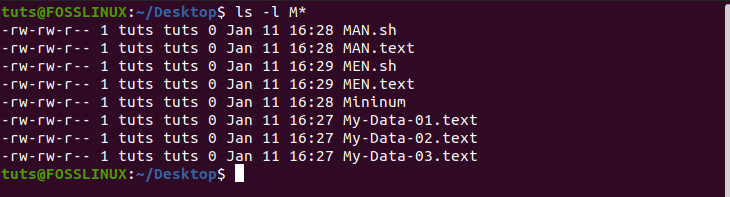
Notice how it only matches the files starting with the uppercase “M” and not lowercase ‘m’.
2. This command will copy all the filenames starting with My-Data and ending with one or multiple occurrences of any character.
$ ls My-Data*
Output:

3. This command will match all files starting with the letter M, ending with the letter N, and having any 1 character in-between.
$ ls M?N.sh
Output:

4. This command will match all files starting with the letter M, ending with the letter N, but having only 1 character in-between belongs to the list of characters defined within the square brackets [AEIOU].
$ ls M[AEIOU]N.sh
Output:

4 Examples of Combining Different Wildcards to Match Filenames
Now, to turbocharge your effectiveness, you can mix and match these wildcards to work together and be more effective at matching filenames.
- Here is a command that will help you find any filename that can have any 3 characters (including no characters) followed by cake and ending with one or more occurrences of any character.
$ ls ???cake*
Output:

2. Here is a command that will match all filenames that start with any of these characters in the square brackets [MNLOP] and end with one or more occurrences of any character.
Let’s also see what happens when we replace [MNLOP] with [mnlop].
So the commands we will be using are:
$ ls [MNLOP]*
$ ls [mnlop]*
Output:
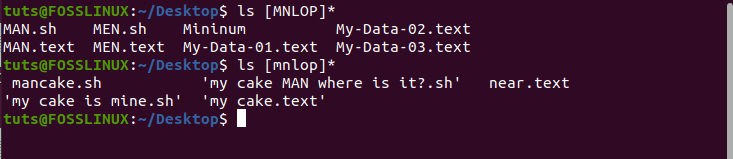
As you can see, you need to be aware of the uppercase and lowercase of the letters you enter into the bracket wildcard as that will influence the result.
3. Here is a command that will match all filenames with any of these characters [MNLOP] as the first one, any of these characters [AEIOU] as the second one, followed by N, and finally ending with one or more occurrences of any character.
$ ls [MNLOP][AEIOU]N*
Output:

Notice how the (*) wildcard is only helping to find all the extensions of the filenames.4.
Here is a command that will match all filenames that starts with one or more occurrences of any character leading to M, followed by any 1 character, then followed by N, and then ending with one or more occurrences of any character.
$ ls *M?N*
Output:

Using Wildcards to Match Characters Set
By now, you should have a working understanding of how wildcards work. We can now focus on some advanced use cases where wildcards are invaluable.
For example, the bracket wildcard allows you to define a range of characters using [-] instead of typing out every character. This can be extremely useful when you want to specify a set of characters and match filenames based on where the characters appear.
To do this, we’ll be using the following set of files, as shown in the image:
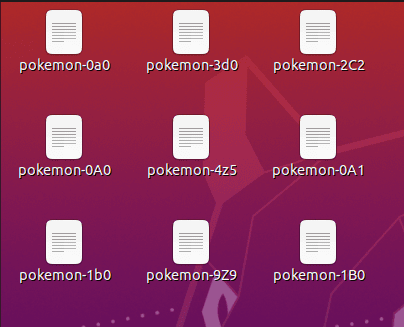
As you can see, the image we have created is a list of files containing different Pokemon data.
Now to find all the filenames that start with pokemon- followed by a number, then any alphanumeric character, again followed by a number, and then ending with one or more occurrences of any character, we can use the following command:
$ls pokemon-[0-9][0-9a-zA-Z][0-9]*
Output:

The part [0-9] represents any numeric characters between 0 to 9.
The next part [0-9a-zA-Z] represents any number of characters between 0 to 9, or any lowercase letter between a to z, or an uppercase letter between A to Z.
As such, if we switch out [0-9a-zA-Z] with [0-9a-z], you can see that the result doesn’t include any filename with the uppercase letters in the designated position.
$ls pokemon-[0-9][0-9a-z][0-9]*
Output:

Using Wildcards to Negate a Set of Characters
Like you can specify a set of characters, you can also negate a set of characters while matching for file names. Here is an example of how it’s done:
$ls pokemon-[0-9][!a-z][0-9]*
Output:

This matches all the filenames that start with pokemon- followed by any numeric character, then by any character other than lowercase letters, followed by any numeric character, and finally ending with one or more occurrences of any character.
Using [!a-z], we are negating the set of all lowercase letters. Now, the file names are matched for any character that’s not a lowercase letter.
Wrapping Up
So that brings us to the end of our quick look at Linux wildcards and how to use them. Summing up everything, in a nutshell, the asterisk (*) wildcard is most useful when you know the filename but not the extension. The question mark (?) wildcard can help you out if you forget a few filename characters. The bracket ([]) wildcard is useful when you want to contain your search within a set of defined characters.
1 comment
You do not define the “!” wildcard character along with all other wildcards.
Also “!” does not “negate” characters. It cause any files names that contain those characters to be ignored by the search.