
Bash is a powerful scripting language that is widely used for automating tasks and processing data in the Linux environment. In this article, we will explore how to use Bash to process and analyze data from text files. Text files are a common data format used in many applications, including data logs, configuration files, and data exports from databases and other software. Bash provides a rich set of tools and commands for working with text files, including tools for searching, filtering, and manipulating data. By using Bash, we can automate these tasks and process data more efficiently.
Where to find the log files in Linux?
In most Linux distributions, log files are stored in the /var/log directory by default. This directory contains logs for various system services and applications. Here are some of the commonly used log files:
- /var/log/syslog: This file contains system-wide messages and error messages.
- /var/log/auth.log: This file contains information about authentication-related events, such as successful and failed login attempts.
- /var/log/kern.log: This file contains kernel-related messages and error messages.
- /var/log/dmesg: This file contains the kernel ring buffer messages, which provides diagnostic information about the system hardware during boot.
- /var/log/apt/term.log: This file contains the output of the apt-get command, which is used for package management.
- /var/log/apache2/error.log: This file contains error messages generated by the Apache web server.
To view the contents of a log file, you can use the “less” or “tail” command in the terminal. For example, to view the contents of the syslog file, you can run the command “less /var/log/syslog” or “tail -f /var/log/syslog” to continuously monitor new log entries as they are written to the file.
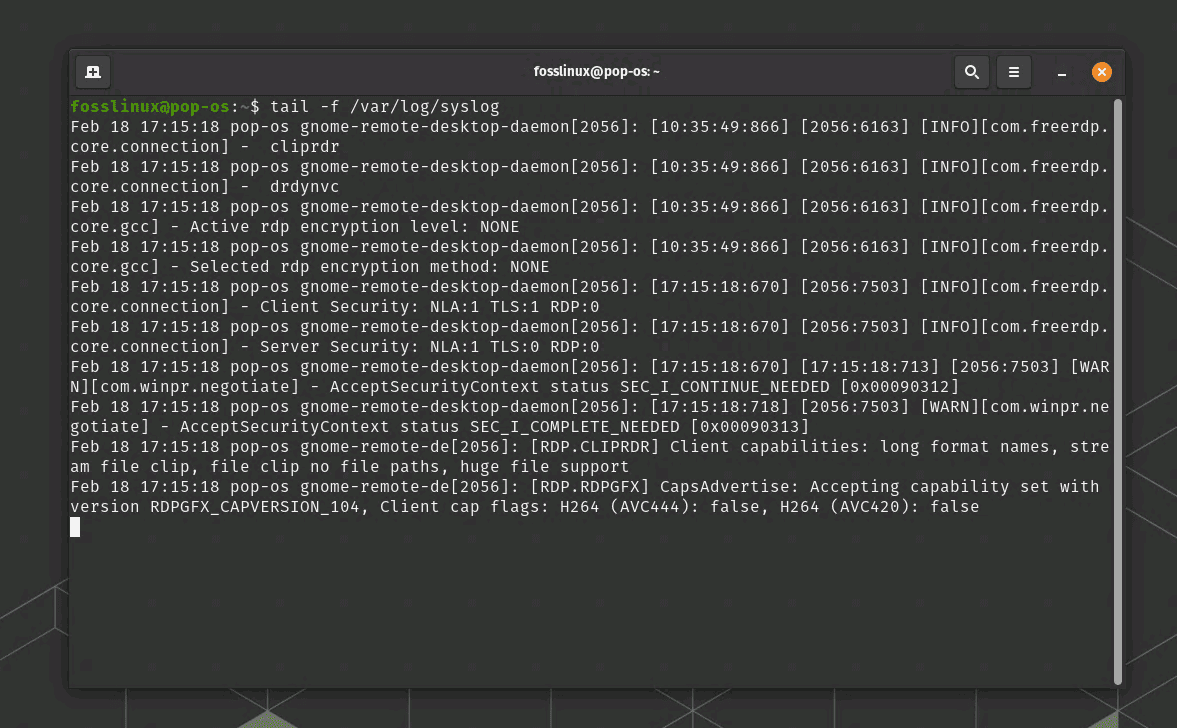
Linux log file example
Exporting the log file to a text file
To export the content of the syslog log file generated by the “tail -f /var/log/syslog” command, you can use the “tee” command to display the content on the terminal and save it to a file at the same time. Here’s an example of how you can use the “tee” command to achieve this:
tail -f /var/log/syslog | tee syslog_output.txt
This command will display the contents of the Syslog log file on the terminal in real-time, and also save the output to a text file named “syslog_output.txt” in the current working directory. The “tee” command copies the output to both the terminal and the specified file, allowing you to view the log file and save it to a file simultaneously. You can replace “syslog_output.txt” with the desired file name and path for the output file.
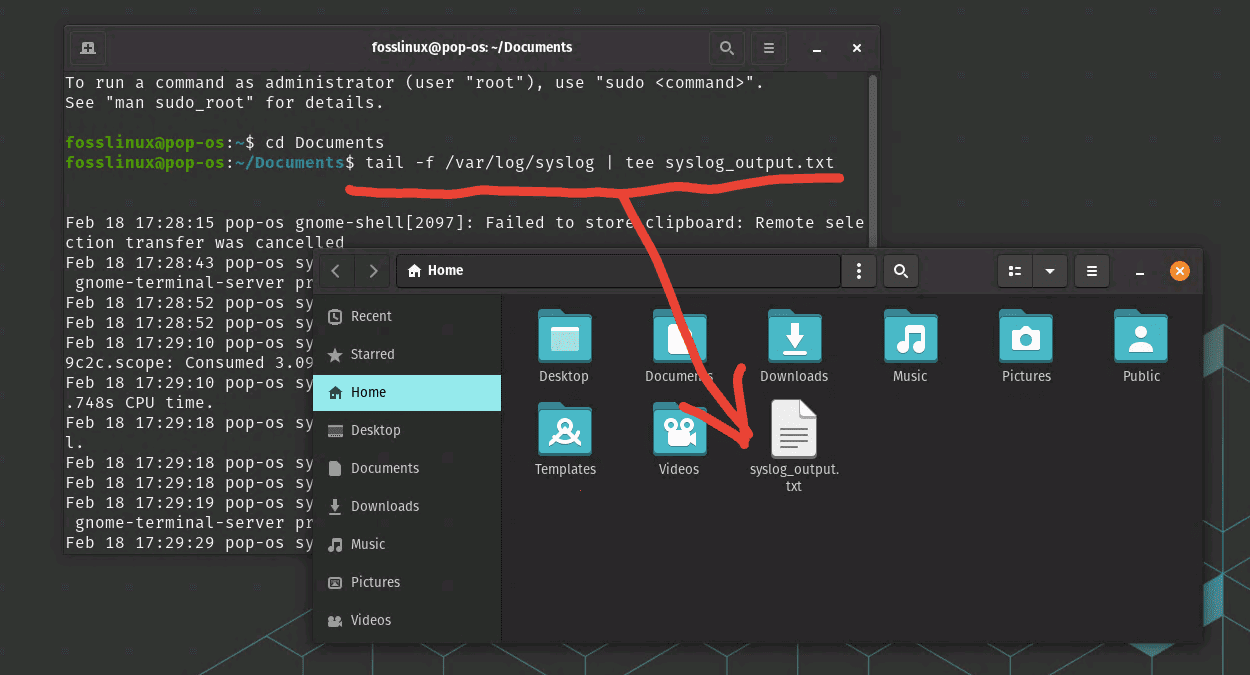
View and export the syslog output to a text file
To end the “tail -f” command that is running in the terminal, you can use the keyboard shortcut “Ctrl + C”. This will send a “interrupt” signal to the running command and terminate it. When you press “Ctrl + C”, the command will stop running, and you will see the command prompt again in the terminal.
All right, now that you have the system log file, let’s get into business and look at various ways to process and analyze it.
Using Bash to process and analyze data from text files
In this article, we will cover the following topics:
- Reading and writing data to text files
- Searching and filtering text data using regular expressions
- Manipulating text data using Bash commands
- Aggregating and summarizing data using Bash commands
1. Reading and writing data to text files
Reading and writing data to text files is a fundamental task when working with data in Bash. Bash provides several commands to read data from text files, such as “cat” and “less”, and to write data to text files, such as “echo” and “printf”. These commands are used to manipulate data in text format, which is a common format for data storage and exchange. By using these commands, we can read and write data to and from text files, and manipulate the data using other Bash commands and tools.
Let’s start with an illustrative example.
The first step in processing and analyzing data from text files is to read the data into our script. Bash provides several commands for reading data from text files, including the “cat” and “read” commands.
The “cat” command is used to display the contents of a text file. For example, the following command will display the contents of a file called “data.txt”:
cat data.txt
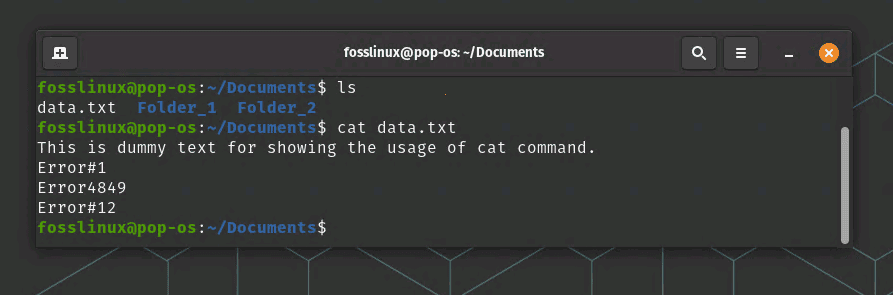
Reading a text file using Cat command
The “read” command is used to read input from the user or from a file. For example, the following command will read a line of text from the user and store it in a variable called “input”:
read input
Once we have read data from a text file, we can process it using Bash commands and tools.
2. Searching and Filtering Text Data using Regular Expressions
Regular expressions are a powerful tool for searching and filtering text data in Bash. Regular expressions are patterns of text that match specific sequences of characters, and they are used to search for specific patterns of text in a file. Bash provides several commands that support regular expressions, such as “grep” and “sed”. The “grep” command is used to search for specific patterns of text in a file, while the “sed” command is used to search and replace specific patterns of text in a file. By using regular expressions in Bash, we can efficiently search and filter text data, and automate tasks that involve searching and filtering data.
For example, the following command will search for all lines in a file called “data.txt” that contain the word “error”:
grep "Error" data.txt
In our example, the following command will replace all occurrences of the word “error” with the word “warning” in a file called “data.txt”:
sed -i 's/Error/warning/g' data.txt
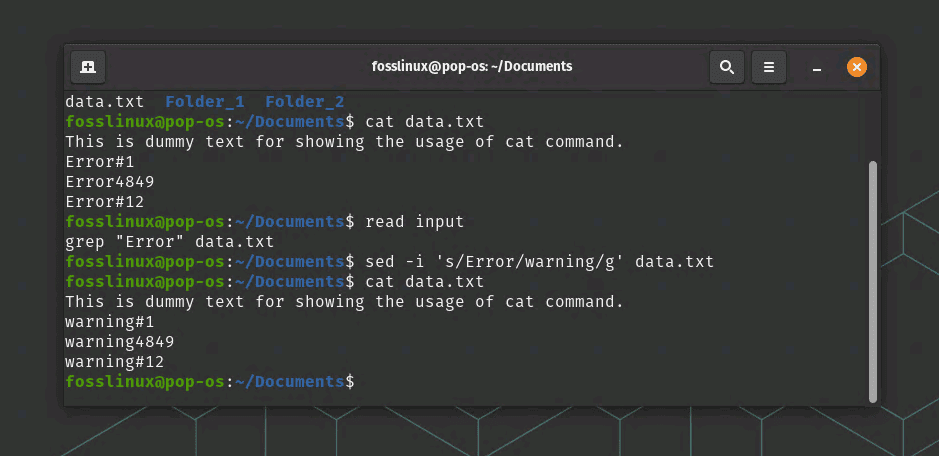
Reading and Replacing text in a file
In this command, the “-i” option tells “sed” to modify the file in-place, and the “s/error/warning/g” argument tells “sed” to replace all occurrences of the word “error” with the word “warning”.
3. Manipulating Text Data using Bash Commands
Bash provides many built-in commands for manipulating text data, which include commands for manipulating text formatting, text substitution, and text manipulation. Some of the most commonly used commands for manipulating text data in Bash include “cut”, “awk”, and “sed”. The “cut” command is used to extract specific columns of text from a file, while the “awk” command is used to perform more complex text manipulation, such as filtering and reformatting text data. The “sed” command is used to perform text substitutions, such as replacing text with new text. By using these commands and other built-in tools, we can manipulate text data in many ways, and perform complex tasks that involve text processing and manipulation.
The following command will extract the second column of data from a file called “data.txt”:
cut -f 2 data.txt
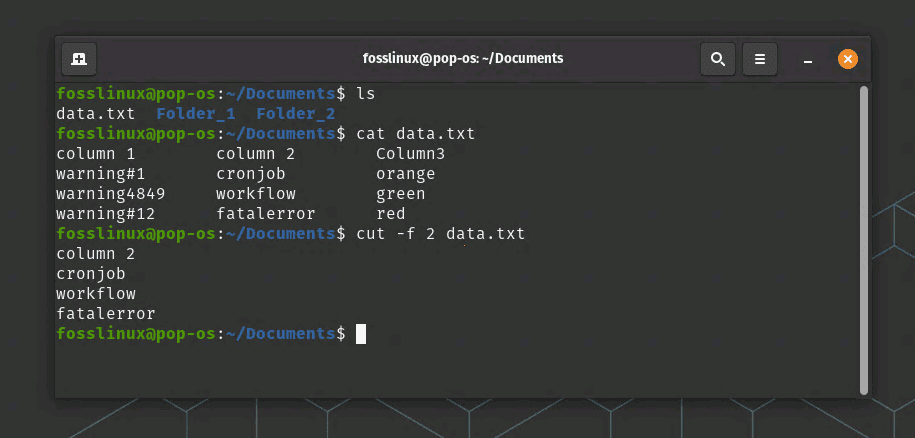
cut command extracts 2nd column data in this example
The “sort” command is used to sort data in text files. For example, the following command will sort the contents of a file called “data.txt” alphabetically:
sort data.txt
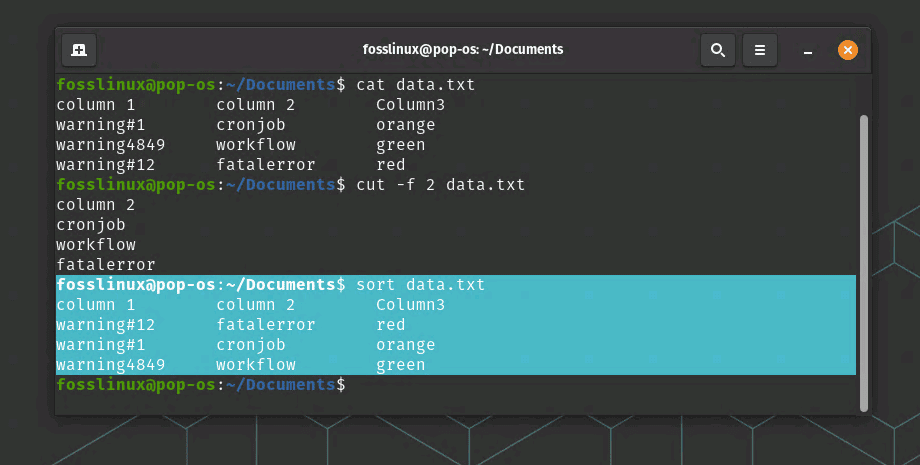
Sort command usage
The “awk” command is a powerful command for manipulating and transforming text data. For example, the following command will print the first and third columns of data from a file called “data.txt” where the second column is greater than 10:
awk '$2 > 10 {print $1,$3}' data.txt
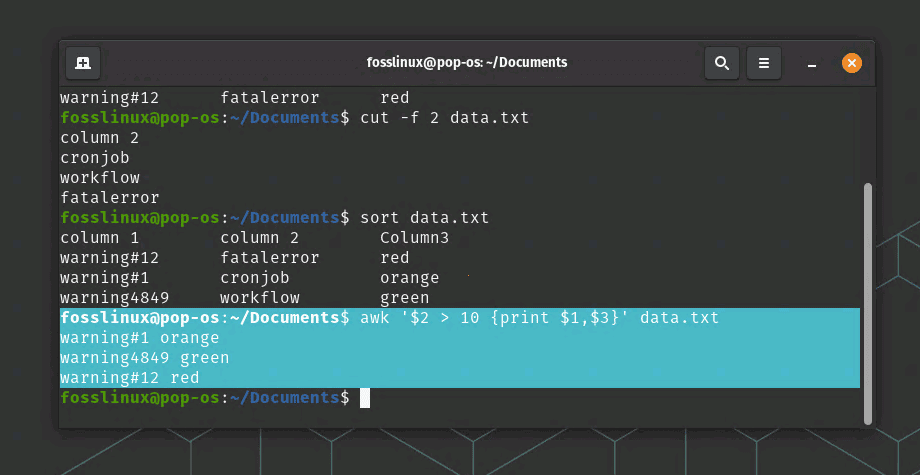
awk command usage
In this command, the “$2 > 10” argument specifies a condition to filter the data, and the “{print $1,$3}” argument specifies the columns to display.
4. Aggregating and Summarizing Data using Bash Commands
In addition to manipulating and transforming data, Bash provides several commands for aggregating and summarizing data. The “uniq” command is used to find unique lines in a file, which can be useful for deduplicating data. The “wc” command is used to count the number of lines, words, and characters in a file, which can be useful for measuring the size and complexity of data. The “awk” command can also be used for aggregating and summarizing data, such as calculating the sum or average of a column of data. By using these commands, we can easily summarize and analyze data, and gain insights into the underlying patterns and trends in the data.
Let’s continue with our example:
The “uniq” command is used to find unique lines in a file. For example, the following command will display all unique lines in a file called “data.txt”:
uniq data.txt
The “wc” command is used to count the number of lines, words, and characters in a file. For example, the following command will count the number of lines in a file called “data.txt”:
wc -l data.txt
The “awk” command can also be used for aggregating and summarizing data. For example, the following command will calculate the sum of the third column of data in a file called “data.txt”:
awk '{sum += $3} END {print sum}' data.txt
In this command, the “{sum += $3}” argument specifies to add up the values in the third column, and the “END {print sum}” argument specifies to print the final sum.
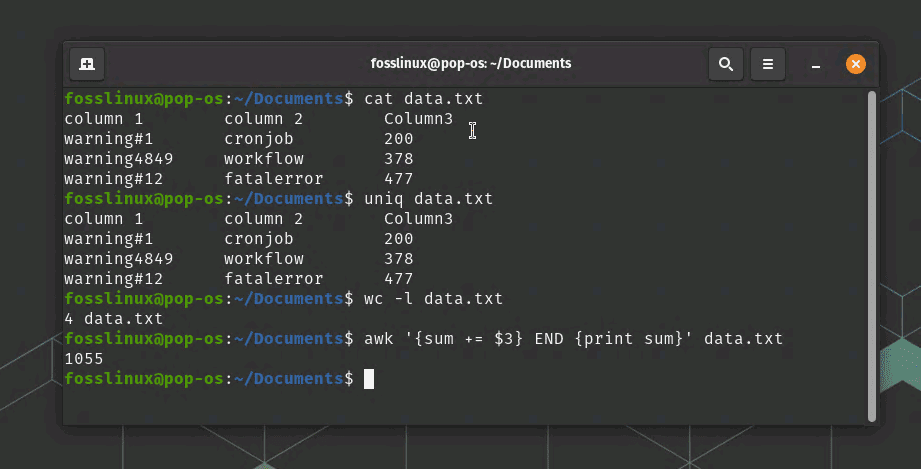
Processing data example
Real-world application scenario
One real-world scenario where Bash can be used to process and analyze data from text files is in the field of web analytics. Websites generate vast amounts of log data, which contain information about the users, their activities, and the performance of the website. This data can be analyzed to gain insights into the user behavior, identify trends and patterns, and optimize the website performance.
Bash can be used to process and analyze this data by reading the log files, extracting relevant information using regular expressions, and then aggregating and summarizing the data using built-in Bash commands. For example, the “grep” command can be used to filter log data for specific user activities, such as page views or form submissions. The “cut” command can then be used to extract specific columns of data, such as the date and time of the user activity or the URL of the page visited. Finally, the “awk” command can be used to calculate the number of page views or form submissions per day or per hour, which can be used to identify peak usage times or potential performance bottlenecks.
By using Bash to process and analyze web log data, website owners can gain valuable insights into the user behavior, identify areas for optimization, and improve the overall user experience.
Conclusion
In this article, we have explored how to use Bash to process and analyze data from text files. By using Bash commands and tools, we can automate tasks, search and filter data using regular expressions, manipulate and transform data using built-in commands, and aggregate and summarize data.
Bash is a powerful language for processing text data, and it provides many tools and commands for working with text files. With a little bit of practice, you can become proficient in using Bash for processing and analyzing data from text files.