
cURL is a command-line utility that developers use to transfer data via several network protocols. Client URL (cURL) or (curl) is considered a non-interactive web browser that uses URL syntax to transfer data to and from servers. It can pull information from the internet and display it in your terminal or save it to a file in your local drive.
This is essentially what web browsers like Firefox or Chromium do, except they render the information. However, curl downloads and displays basic information. Curl is powered by ‘libcurl’, a free and easy-to-use client-side URL transfer library.
cURL works without user interaction, unlike popular web browsers like Firefox. To use cURL, you launch the curl command while at the same time you issue the web address. You also have to specify if you want the data saved to a file or displayed in the terminal. Therefore, using curl for novice users can create a few challenges, especially when interacting with a site that requires authentication or an API.
Accessing the internet with the curl command
The article guides some common curl commands and syntax to get the most out of the curl command.
cURL protocols
The curl command is very versatile. It can transfer data to or from a server using its long list of supported protocols such as HTTP, DICT, FTP, FILE, SFTP, FTP, GOPHER, IMAP, IMAPS, POP3, LDAP, RTMP, RTSP, SMB, SMBS, SMTP, TELNET, and TFTP. Note, cURL uses HTTP by default if you do not specify a protocol.
Installing curl
The curl command is installed by default in Linux distros. You can check if you already have curl installed by typing ‘curl’ in your terminal and pressing ‘enter’. If you already have it installed, the following message will appear:
[fosslinux@fedora ~]$ curl curl: try 'curl --help' or 'curl --manual' for more information
How to use cURL
Curl syntax:
Curl [option] [url]
List contents of a remote directory
You can use curl to list the contents of a remote directory if the remote server allows it. Listing content is essential since cURL is non-interactive, and it might be challenging to browse web pages for downloadable files.
$ curl --list-only "https://foofoo.com/foo/"
Download files with curl command
You can download a file with curl by providing a specific content URL. If your URL defaults to index.html, then the index page is downloaded. The downloaded file displays on your terminal screen. The curl command also provides several options to pipe the output to less or tail.
[fosslinux@fedora ~]$ curl "http://example.com" | tail -n 6 % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 1256 100 1256 0 0 2012 0 --:--:-- --:--:-- --:--:-- 2009 <p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p> <p><a href="https://www.iana.org/domains/example">More information...</a></p> </div> </body> </html>
Best practice:
- Surround URLs containing special characters with quotation marks.
- Use the –remote-name flag to save your file according to the name on the server.
$ curl --remote-name "https://example.com/linuxdistro.iso" $ ls linuxdistro.iso
- Use the –output option to name your downloaded file.
curl "http://foofoo.com/foo.html" --output bar.html
Save a file download
You can save the content to a file by using curl with the -o flag. It allows you to add a filename to save the URL content.
$ curl -o filename.html http://foofoo.com/filename.html
You can also use curl with the -O option to save a file without specifying the filename. The -O option allows you to save the file under the URL name. To use this option, prefix the URL with a -O.
$ curl -O http://foofoo.com/filename.html
Continue a partial download
If you’re downloading large files, there might be interruptions to the download. However, curl can determine where your download stopped before it continues with the download. cURL comes in handy if you’re downloading large files like a 4GB Linux distro ISO. When there is an interruption, you never have to go back to restart the download.
To continue a download, use the –continue-at option. Moreover, if you know the byte count of the interrupted download, you can provide it; otherwise, use (-) for curl to detect it automatically.
$ curl --remote-name --continue-at - "https://foofoo.com/linuxdistro.iso" OR $ curl -C -O http://foofoo.com/fileo3.html
Download several files
The curl command comes in handy when you want to download a sequence of files. First, you need to provide the address and filename pattern of the files to download. Then, it uses curl’s sequencing notation with the start and endpoint between a range of integers in brackets.
In our example below, #1 indicates the first variable of your output filename.
$ curl "https://foofoo.com/file_[1-4].webp" --output "file_#1.webp"
To represent a different sequence, denote each variable in the order it appears in the command. In the example below, #1 indicates the directories images_000 through images_008, while #2 refers to the files file_1.webp through file_6.webp.
$ curl "https://foofoo.com/images_00[0-8]/file_[1-6.webp" \ --output "file_#1-#2.webp"
Download images
You can combine the curl command with grep for web scraping and download images from a web page. The first step is to download the page that references the desired images. The second step is to pipe the page to grep with searching for the image type (i.e., PNG, JPEG). Next, create a loop (while in our case) to create a download URL and save the image files in your local drive.
[fosslinux@fedora ~]$ curl https://foofoo.com |\
grep --only-matching 'src="[^"]*.[png]"' |\
cut -d\" -f2 |\
while read i; do \
curl https://example.com/"${i}" -o "${i##*/}"; \
done
Fetch HTML headers
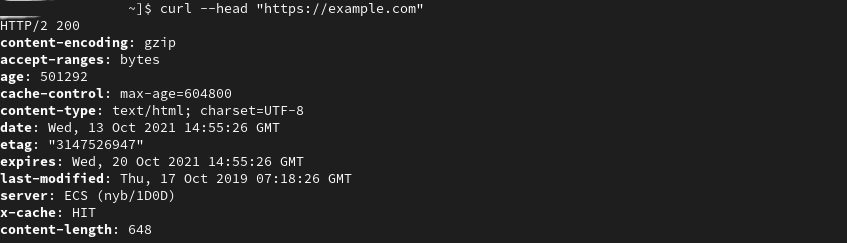
You can use cURL to fetch and view HTTP headers. You can then use the response codes to troubleshoot your connection to a website. HTTP headers contain metadata embedded in the packets that computers or devices send to communicate.
The example below uses the curl –head flag to view HTML headers metadata of “https://example.com”.
[fosslinux@fedora ~]$ curl --head "https://example.com" HTTP/2 200 content-encoding: gzip accept-ranges: bytes age: 414742 cache-control: max-age=604800 content-type: text/html; charset=UTF-8 date: Mon, 11 Oct 2021 11:09:04 GMT etag: "3147526947" expires: Mon, 18 Oct 2021 11:09:04 GMT last-modified: Thu, 17 Oct 2019 07:18:26 GMT server: ECS (nyb/1D23) x-cache: HIT content-length: 648
curl –head
Fail quickly
Contacting a web page usually returns 200 to indicate success, a 404 response if a page can’t be found, or a 500 response when there is a server error. In addition, you can view what errors are happening during negotiation using the –show-error flag.
[fosslinux@fedora ~]$ curl --head --show-error "http://fosslinux.com"
You can also force curl to exit quickly upon failure using the –fail-early flag. Fail soon comes in handy when testing a connection over a network when the endless retries waste your time.
[fosslinux@fedora ~]$ curl --fail-early "http://fosslinux.com"
Redirect a query from a 3xx HTTP response code
The curl command gives you more flexibility when there is a 300 series HTTP response code. A 301 HTTP response code usually signifies that a URL has been moved permanently to a different location. It gives web admins the ability to relocate content while leaving a “trail” so users visiting the old address can still find the content they are searching for. However, the curl command doesn’t follow a 301 redirect by default, but you can make it continue to a 301 destination by adding the –location flag.
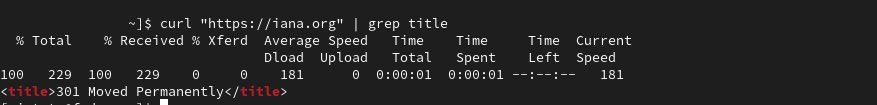
curl | grep
[fosslinux@fedora ~]$ curl "https://iana.org" | grep title <title>301 Moved Permanently</title> [fosslinux@fedora ~]$ curl --location "https://iana.org" <title>Internet Assigned Numbers Authority</title>
Expand a shortened URL
You can combine curl with the –location flag to view shortened URLs before visiting them. Shortened URLs are essential in social networks or print media to help users copy and paste long URLs. You can combine the –head flag (view the HTTP headers) and the –location flag (view final destination of a URL) to peek into a shortened URL without loading the complete resource.
$ curl --head --location \ "https://bit.ly/2xTjD6S"
Web scraping with cURL and PHP
You can use PHP and cURL to do simple web scraping using bots to extract data from a website. You can use cURL to make HTTP requests with PHP. In essence, it gives you a way to call web pages from within your scripts. You can use cURL and web scraping to automate the long, tedious, and repetitive tasks.
Disclaimer: You should only scrape information, not complete articles and content. It would be best if you always abode by a websites’ rules. Moreover, do not access password-protected content, which is most certainly illegal.
How to make a cURL GET request
The example below will create a cURL request to a server to get the source code of a web page. You can then perform a web scrape of the data you require from the web page.
Step 1: Create a new file with the .php extension (i.e. curl_simple_request.php) and enter the following code.
<?php
// GET request function using cURL
function simpleCurlGet($url) {
$ch = curl_init(); // Initialise the cURL session
// Set cURL options
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($ch, CURLOPT_URL, $url);
$scrape_results = curl_exec($ch); // Execute the cURL session
curl_close($ch); // Close the cURL session
return $scrape_results ; // Return the results
}
$FOSSLINUXPAGE = simpleCurlGet('https://fosslinux.com/12#34');
echo $FOSSLINUXPAGE;
?>
Step 2: Save the file and execute the PHP script.
Step 3: Let the script complete to view the source code of the requested URL [https://fosslinux.com/12#34].
Notes:
- The function simpleCurlGet($url) accepts a single parameter $url (URL of the resource requested.
- The $ch = curl_init(); code initializes a new cURL session.
- The code, curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);, let’s cURL return the results of the requested resource as a string.
- The curl_setopt($ch, CURLOPT_URL, $url) code initializes the resource URL you wish to request. Note, the $url variable is passed into the function as a parameter.
- $scrape_results = curl_exec($ch) executes the cURL request and stores the returned string in the $scrape_results variable.
- The code, curl_close($ch) is used to close the cURL session.
- The code, return $scrape_results will return the $scrape_results variable containing the requested page.
- To execute the function, pass the URL as a parameter and store the returned data from the function in the $FOSSLINUXPAGE variable.
- Echo the contents of the requested resource from the $FOSSLINUXPAGE variable with echo $FOSSLINUXPAGE.
Other common cURL options
cURL provides other essential options available for you to use. The table below highlights other options that you can try out.
| cURL option | Value | Purpose |
|---|---|---|
| CURLOPT_FAILONERROR | TRUE or FALSE | cURL will fail silently if a response code greater than 400 is returned. |
| CURLOPT_FOLLOWLOCATION | TRUE or FALSE | If Location: headers are sent by the server, follow the location. |
| CURLOPT_USERAGENT | A user agent string. For example, 'Mozilla/5.0 …. Gecko/20100111 Firefox/15.0.1' | Sending the user agent string in your request informs the target server of the client requesting the resource. |
| CURLOPT_HTTPHEADER | An array containing header information. For example, for example: array('Cache-Control: max-age=0', 'Connection: keep-alive', 'Keep-Alive: 300', 'Accept-Language: en-us,en;q=0.6') | It is used to send header information with a request. |
Find more cURL options on the PHP website.
HTTP response code values
An HTTP response code is a number returned that corresponds with the result of an HTTP request. Some essential HTTP response code values include the following:
- 200: OK
- 301: Moved Permanently
- 400: Bad Request
- 401: Unauthorized
- 403: Forbidden
- 404: Not Found
- 500: Internal Server Error
It is important for web admins to have scrapers that respond to different response code values. In our PHP cURL script above, you can access the HTTP response of a request by adding the following code, ($httpResponse = curl_getinfo($ch, CURLINFO_HTTP_CODE);) , to the (simpleCurlGet($url) function. The code will store the response code in the $httpResponse variable.
HTTP responses are essential for web admins and can let you know if a web page is no longer accessible, or has moved, or if you are unauthorized to access a requested page.
Wrapping up
cURL is an essential tool for novice terminal users, a convenience, and a quality assurance tool for sysadmin and cloud developers working with microservices. Curl is installed by default in most Linux distros and is the go-to tool for complex operations. Moreover, there are other alternatives like ‘wget‘ or ‘Kurly’ that we will highlight in our upcoming articles.
Learn more about cURL from the official cURL manpage.